We have raised $7.5M to accelerate RLOps for enterprise AI.
Read more in Business Insider

Arena unifies training, tuning, and deployment, allowing teams to ship to production faster.
Trusted by leading teams in research, defense, finance, robotics and logistics.




Train and deploy AI agents faster than ever with Arena's state-of-the-art reinforcement learning tooling.
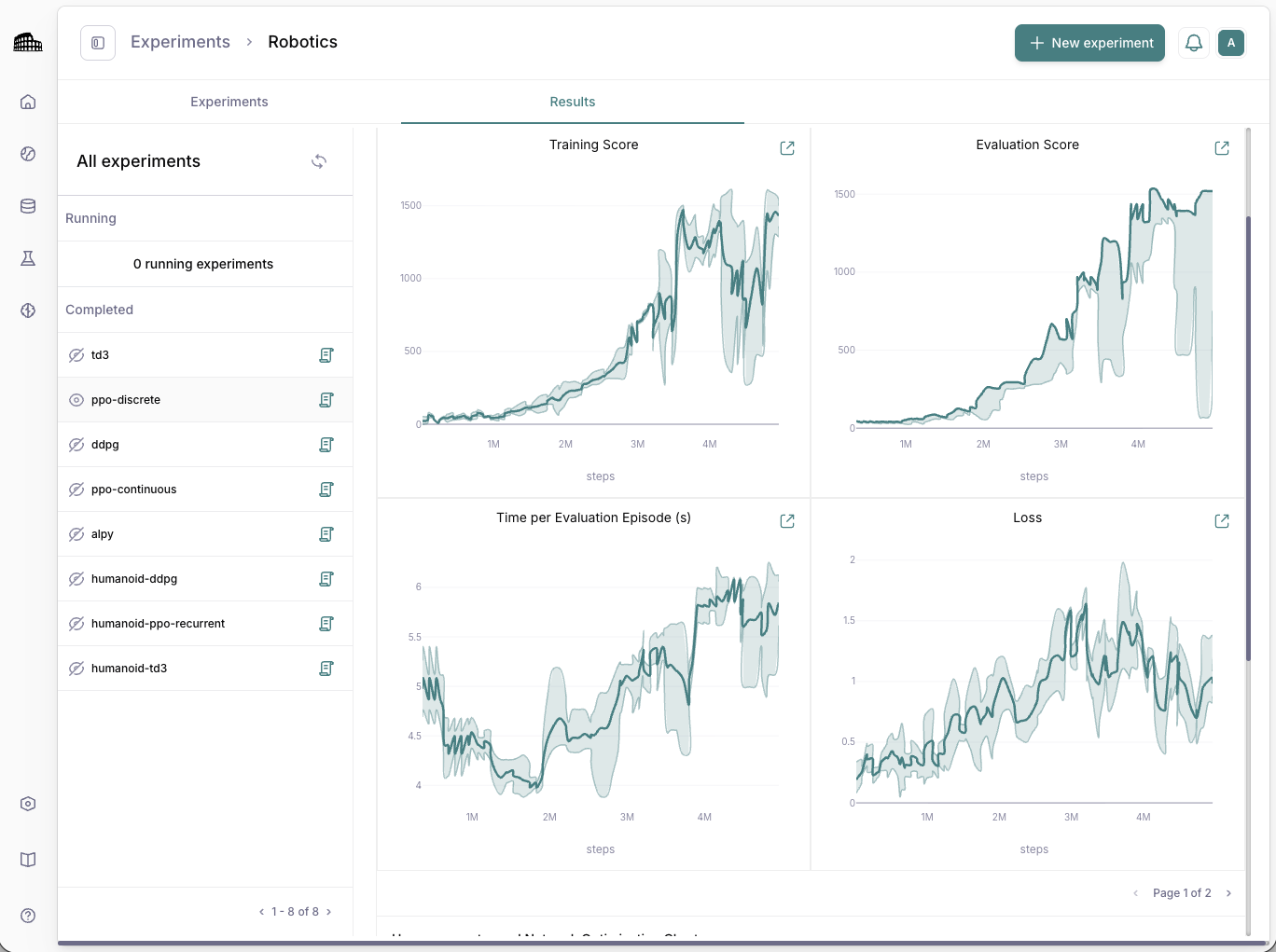
Evolutionary hyperparameter optimization and distributed training on any single- or multi-agent task.
Fine-tune LLMs using evolutionary HPO and one-click deployment. Train custom models on your data without infrastructure hassle.
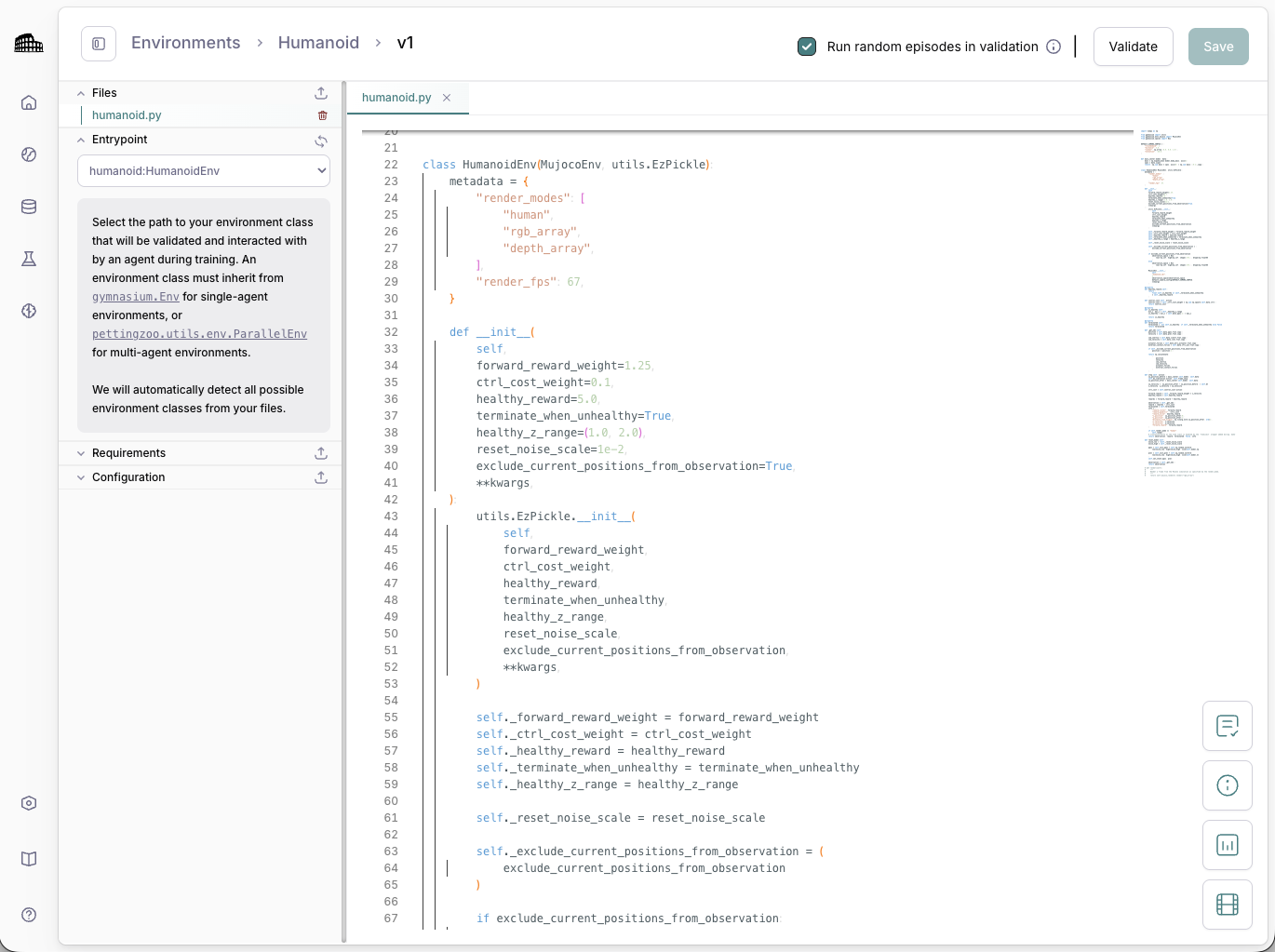
Validate your dataset or environment before training to ensure everything runs as intended.
RL stacks sprawled across notebooks, scripts, and bespoke infrastructure
Hyperparameter search is slow and ad-hoc
Environment mismatches derail runs late into the pipeline
Shipping trained policies into production is brittle and manual


A single platform to train, evaluate, and deploy
Built-in evolutionary tuning to converge faster, with better results
Pre-flight environment validation before you spend
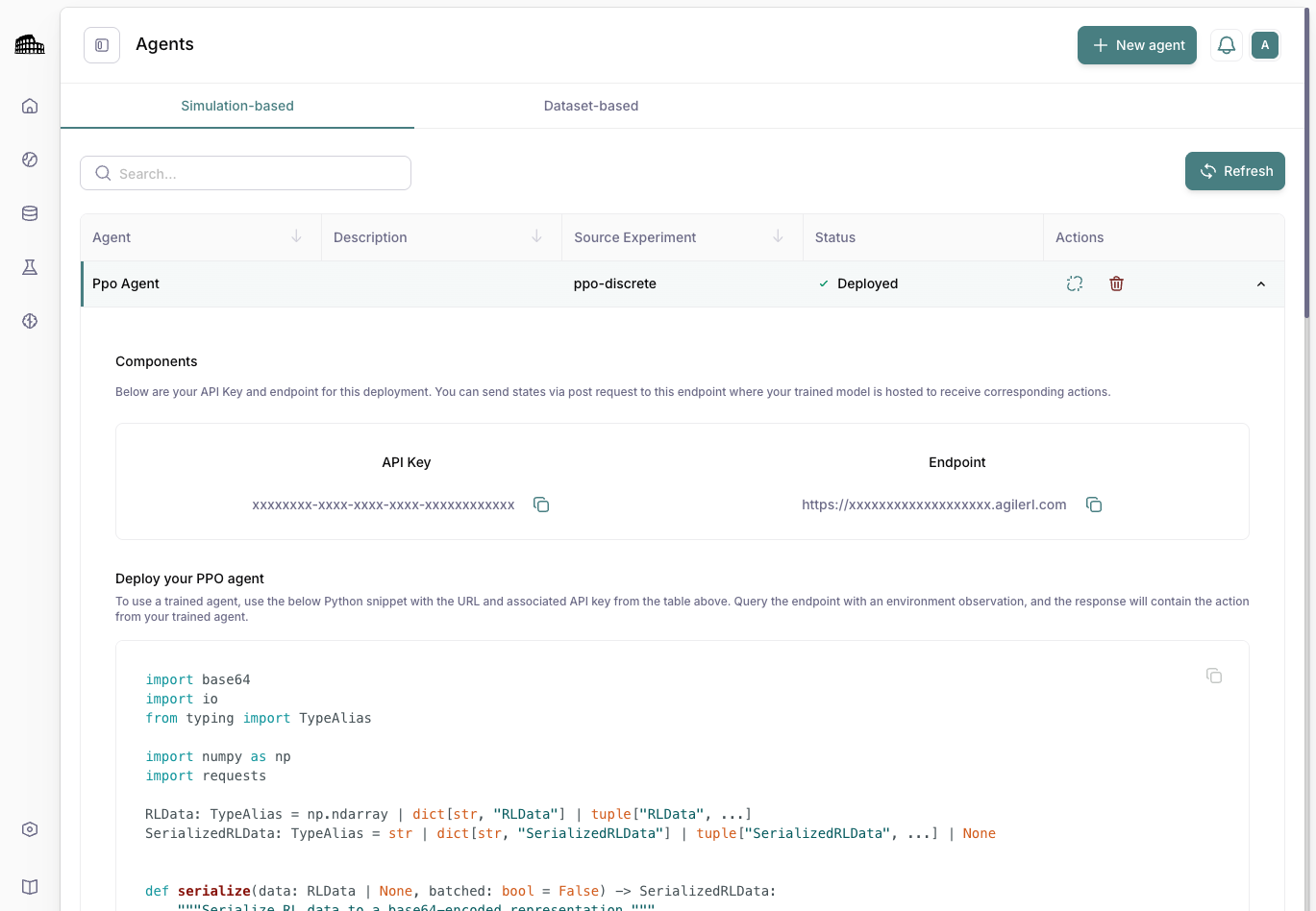
Hosted, one-click deployment for live inference at scale

Upload your LLM dataset or Python environment; validate your environment before training begins to ensure runs don’t fail hours in.

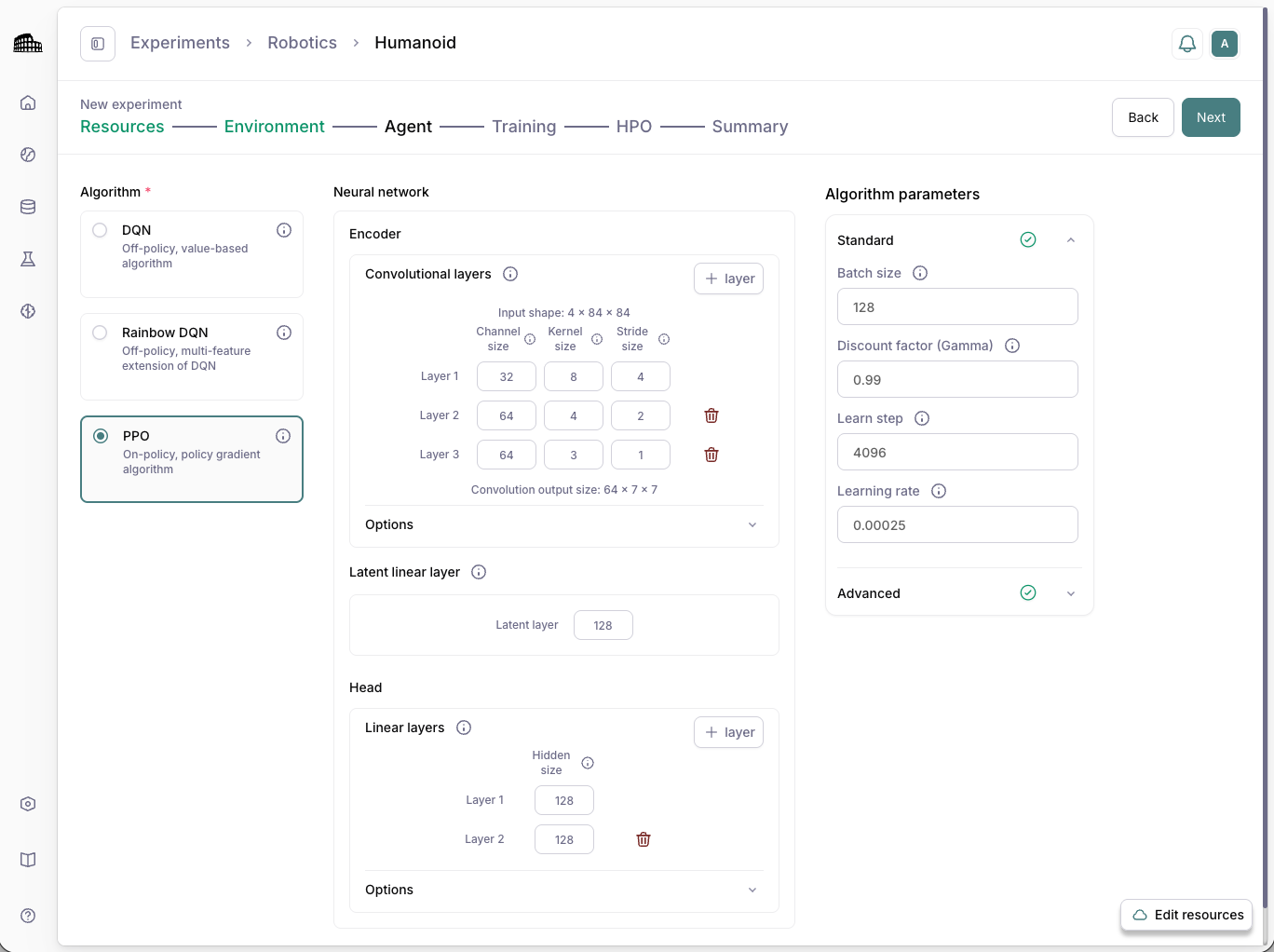
Select algorithms, rewards, constraints, and objectives; enable evolutionary tuning to explore promising configurations automatically.

Distribute across available GPUs/ instances; monitor metrics, sample efficiency, and checkpoints in real time.

One-click promote to production; track performance, roll back, or iterate with easy-to-buy training credits.
Enabling breakthrough results in training AI agents for complex aerial interception missions with RTDynamics
Substantially cutting compute expenses and boosting training speed for RL workflows with Warburg AI
Dramatically increasing utilisation and reducing training time for complex bin-packing with Decision Lab


Open-source framework with docs, examples, and community support
Single and multi-agent support across on/off-policy, offline RL, bandit and LLM training
Python-first, compatible with custom environments
Works with your cloud compute and scales to multi-GPU
Training with open-source v2

Used by leading research
labs and institutions
Downloads from the community
Top up training credits anytime - no plan change required. Get credits.

Built-in evolutionary HPO for smarter, faster training.
One-click deployment from experiment to production.
Distributed training at scale with multi-GPU support.
Reinforcement fine-tuning for LLMs.
Bring a sample environment or dataset and we will walk you through training, tuning, and deployment in a live session tailored to your use case.
Book a demo