Transforming Autonomous Systems with AgileRL
RTDynamics Develops AI-Powered Interception Agents on Arena
RTDynamics Develops AI-Powered Interception Agents on Arena
In the rapidly evolving field of autonomous defence systems, where training efficiency and simulation accuracy directly impact deployment readiness, the right reinforcement learning platform can fundamentally transform development timelines. For RTDynamics, a specialist in high-fidelity flight simulation, integrating their RotorLib CGF helicopter dynamics model with AgileRL Arena enabled breakthrough results in training AI agents for complex aerial interception missions.

RTDynamics specialises in constructing computer generated forces (CGF) and high-fidelity rotorcraft simulation through their RotorLib platform. Their goal was to demonstrate how AI agents could be trained to control quadcopters for defensive interception missions. This is a complex task requiring:
- Full 6-DoF flight dynamics: Realistic helicopter physics executing in real-time
- Vectorized environments: Support for parallel training across multiple scenarios
- Flexible control systems: Multiple modes of interception through virtual pilot interfaces
- Rapid iteration: Fast experimentation cycles for different helicopter configurations and mission parameters
Traditional approaches to training such agents would require extensive infrastructure setup, custom RL implementation, and lengthy training cycles that could take weeks to demonstrate proof of concept.
The combination of RTDynamics' high-fidelity simulation and AgileRL Arena's efficient training infrastructure delivered impressive results:
- Faster-than-realtime training: Vectorised environments enable rapid learning cycles
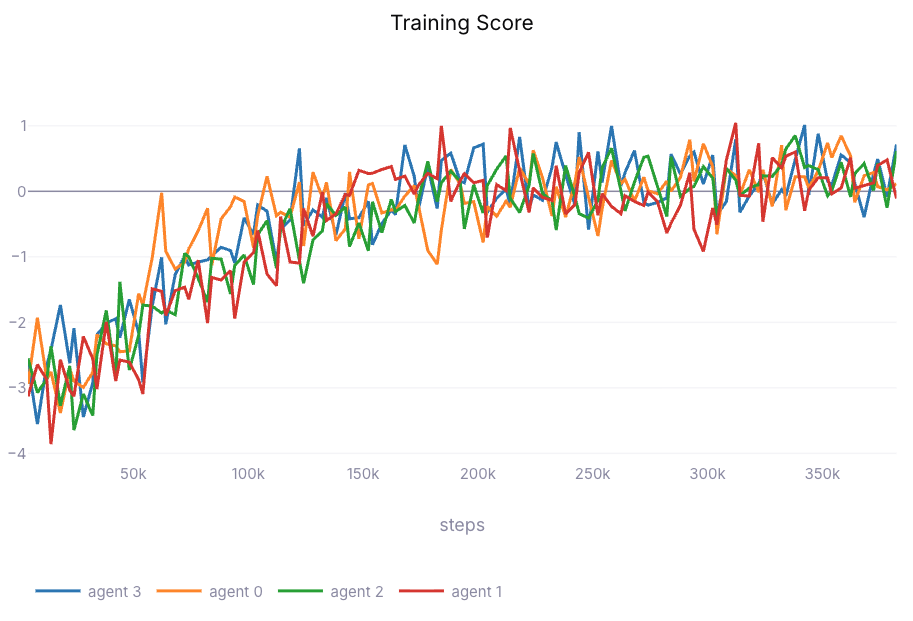
- Successful interception behaviour: Agents learned to pursue, track, and intercept incoming drones
- Adaptive defence: Quadcopter maintains protection of moving ground vehicle while engaging threats
- Robust performance: Trained agent handles variations in target approach angles and speeds
The RTDynamics drone interception environment, including the RotorLib drone simulation, is available from RTDynamics and is immediately compatible with AgileRL Arena. This seamless integration means users can get started quickly without complex setup or custom integration work, leverage Arena's familiar interface and tools with RTDynamics environments, and maintain flexibility to switch between different simulation environments while keeping the same training infrastructure.
What This Means for Defence AI Development:
The combination of RTDynamics' high-fidelity simulation and AgileRL's training platform fundamentally changes the economics of defense AI development. Teams can now prototype new defensive strategies in days rather than months, without the burden of building custom RL training pipelines. The simulation fidelity of RotorLib ensures that agents trained in the environment will transfer effectively to real systems, while the collaborative approach brings together RTDynamics' domain expertise with AgileRL's reinforcement learning capabilities.
The RTDynamics and AgileRL collaboration demonstrates several important principles for autonomous systems development:
- Simulation quality matters: High-fidelity dynamics models enable more effective training and better real-world transfer
- Platform integration is critical: Seamless connection between simulation and RL infrastructure accelerates development
- Flexibility enables innovation: Easy customization of environments and algorithms supports rapid experimentation
- Faster-than-realtime changes economics: Efficient vectorized simulation makes complex AI training practical
As autonomous defence systems become increasingly sophisticated, the combination of RTDynamics' simulation expertise and AgileRL's training platform provides a powerful foundation for developing next-generation AI capabilities.
Ready to train your own AI agents? Contact RTDynamics to access the drone interception environment, or reach out to AgileRL to learn how Arena can accelerate your reinforcement learning projects.
If you would like to take part in a case-study with AgileRL, please reach out on LinkedIn.


